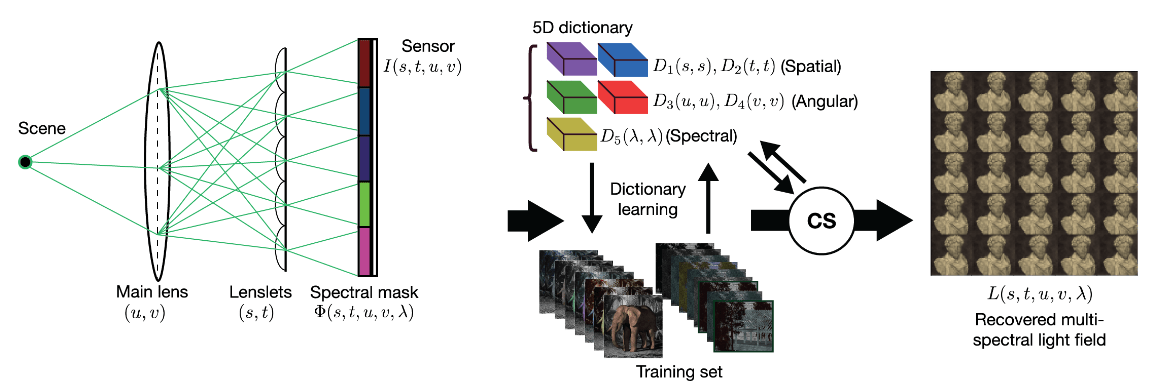
: This paper considers a compressive multi-spectral light field camera model that utilizes a one-hot spectral-coded mask and a microlens array to capture spatial, angular, and spectral information using a single monochrome sensor. We propose a model that employs compressed sensing techniques to reconstruct the complete multi-spectral light field from undersampled measurements. Unlike previous work where a light field is vectorized to a 1D signal, our method employs a 5D basis and a novel 5D measurement model, hence, matching the intrinsic dimensionality of multispectral light fields. We mathematically and empirically show the equivalence of 5D and 1D sensing models, and most importantly that the 5D framework achieves orders of magnitude faster reconstruction while requiring a small fraction of the memory. Moreover, our new multidimensional sensing model opens new research directions for designing efficient visual data acquisition algorithms and hardware.